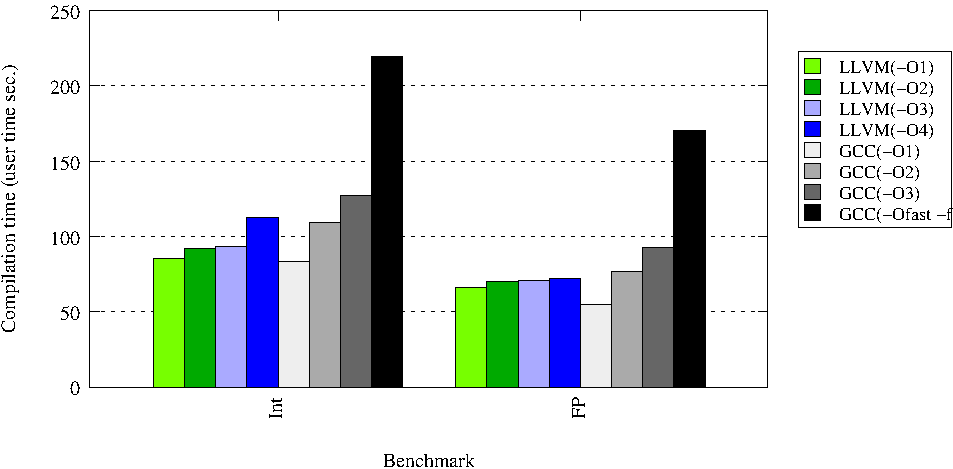
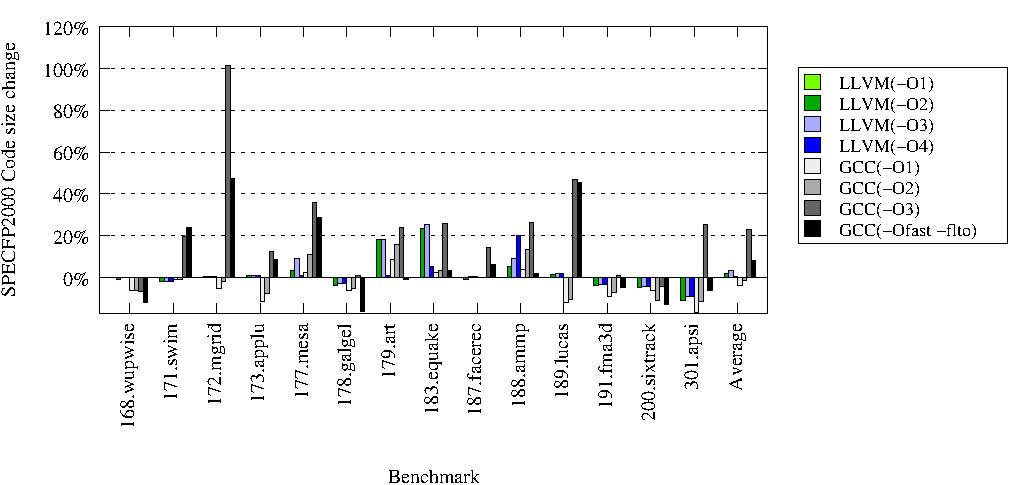
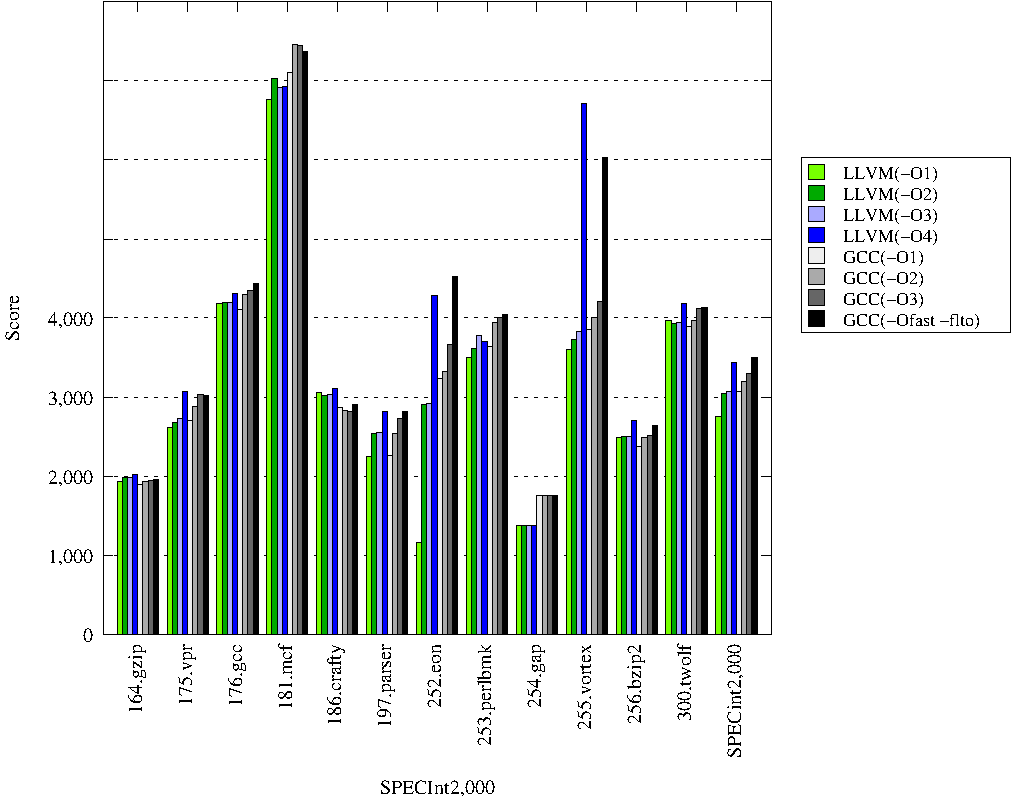
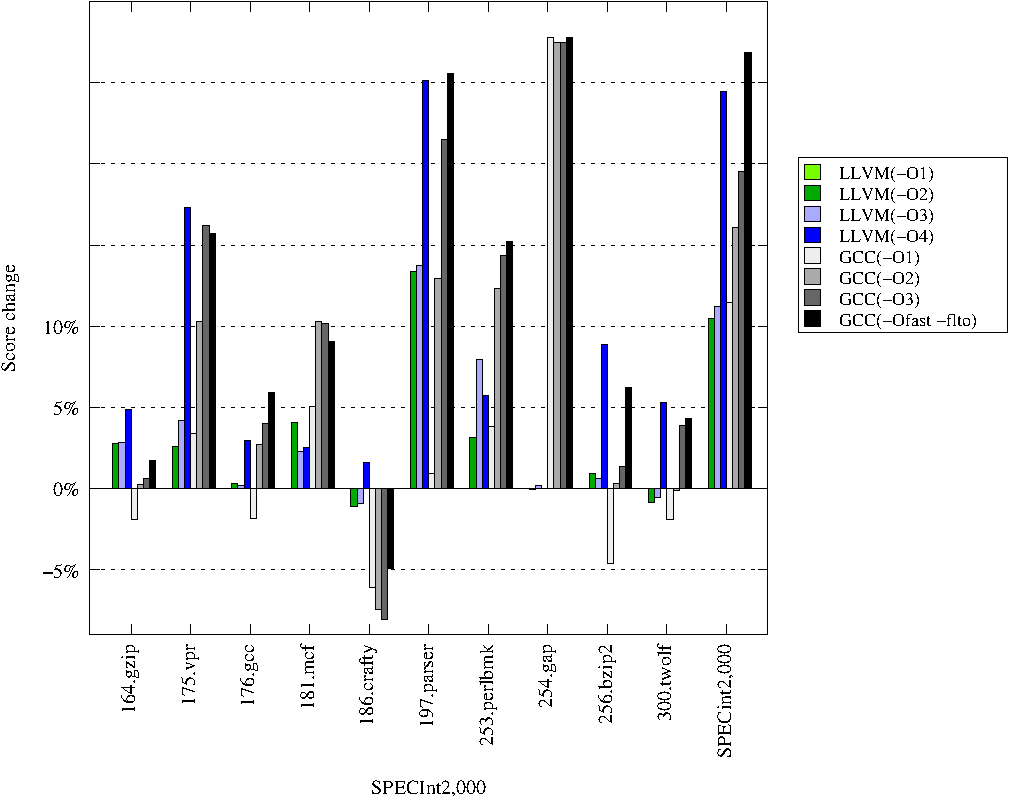
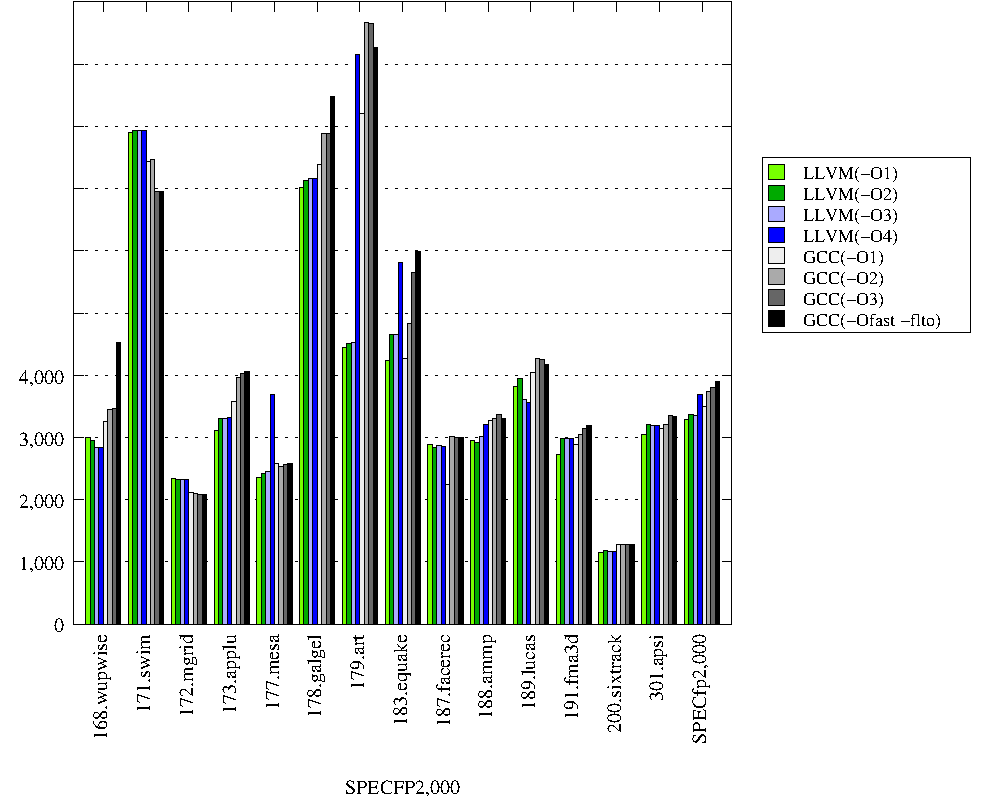
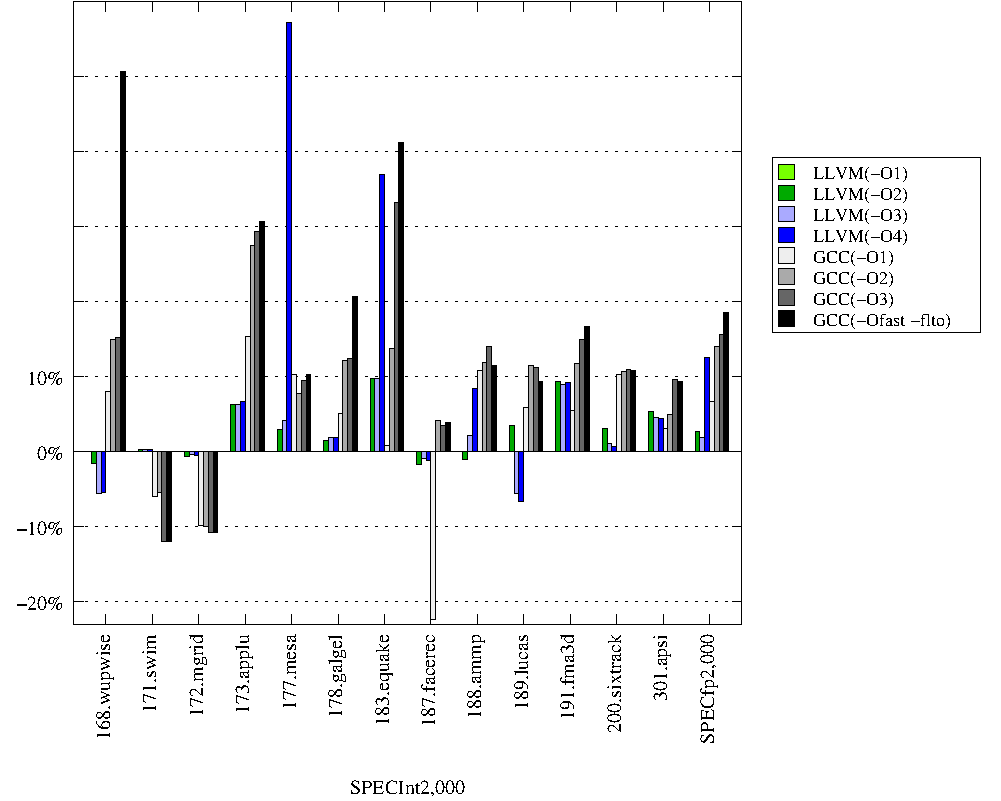
The goal of these runs is to compare the performance of the latest
versions of LLVM and GCC on x86 in 32-bit mode. I used the following
similar options:
- -O1 -mtune=corei7 -march=i686,
-O2 -mtune=corei7 -march=i686,
-O3 -mtune=corei7 -march=i686,
and -O4 -mtune=corei7 -march=i686 for LLVM
- -O1 -mtune=corei7 -march=i686,
-O2 -mtune=corei7 -march=i686,
-O3 -mtune=corei7 -march=i686,
and -Ofast -fno-fast-math -flto -fwhole-program -mtune=corei7 -march=i686 for GCC
GCC -Ofast means -ffast-math by default whereas
LLVM -O4 still uses normal floating point math, therefore GCC
in -Ofast ran with -fno-fast-math to make a correct
comparison. For the same reason LLVM run with -march=i686 as
by default it uses -march=x86-64 when it generates 32-bit
code on x86-64 target.
LLVM can not produce a correct code for 254.gap on any optimization
level. Therefore -O0 was used for both LLVM and GCC for 254.gap.
The used machine is 3.4Ghz Intel Core i7-2600 with 8GB
memory under Fedora Core17.
GCC-4.8 was configured with
--enable-checking=release. LLVM-3.2 with CLANG and
Dragonegg for x86 were built in release mode. The sources are taken
from
LLVM download site.
All changes are given relative to LLVM-3.2 run with -O1.
Last modified: 02/04/2013 - vmakarov at redhat dot com
Return to index page.